
1Einleitung und Problemhintergrund
Warteschlangen sind ein allgegenwärtiges Phänomen in öffentlichen Räumen. Sie entstehen überall dort, wo begrenzte Ressourcen auf schwankende Nachfrage treffen – sei es in Behörden, Krankenhäusern, Einkaufszentren, an Flughäfen oder in gastronomischen Einrichtungen. Lange Wartezeiten können die Kundenzufriedenheit beeinträchtigen und zu Aufgabe oder Abwanderung führen[1].
Die transparente Information über Wartesituationen ist daher ein zentrales Forschungsthema in zahlreichen gesellschaftlichen und wirtschaftlichen Bereichen. Die Forschung im Bereich des Queue Managements beschäftigt sich seit Jahrzehnten mit Methoden zur Messung, Vorhersage und Optimierung von Warteprozessen[2]. Bereits Saaty[3] legte mit seinen grundlegenden Arbeiten zur Warteschlangentheorie die Basis für zahlreiche Anwendungsdomänen. Aktuelle Arbeiten adressieren Bereiche von Banken[4], Apotheken[5], Krankenhäusern[6] und Gastronomiebetrieben[7].
Trotz zahlreicher bestehender Ansätze fehlt es in vielen Alltagssituationen an einer transparenten Echtzeit-Information über die aktuelle Wartesituation. Personen mit begrenztem Zeitbudget – etwa Studierende zwischen Lehrveranstaltungen, Reisende am Flughafen oder Berufstätige in der Mittagspause – stehen dabei regelmäßig vor zentralen Fragen, ob die verfügbare Zeit ausreicht, um sich in eine Warteschlange einzureihen und rechtzeitig bedient zu werden, und ob das gewünschte Produkt zum Zeitpunkt der Bedienung noch erhältlich sein wird. Ausreichende Zeit und Produktverfügbarkeit sind damit die beiden entscheidenden Ausschlusskriterien, anhand derer sich die Sinnhaftigkeit eines Anstellens überhaupt beurteilen lässt.
Eine ungenaue Einschätzung der Wartezeit hat kontraproduktive Effekte: Eine Überschätzung führt dazu, dass Personen ihren Platz in der Schlange aufgeben, während eine Unterschätzung sie weiterhin zum Warten zwingt[8]. Bestehende technische Lösungsansätze weisen spezifische Limitierungen auf: Manuelle Zählsysteme sind fehleranfällig und auf aktive Nutzermitwirkung angewiesen. Sensorbasierte Ansätze – etwa Infrarot, RFID oder LiDAR – bieten zwar höhere Automatisierung, erfordern jedoch kostspielige Spezialhardware. Kamerabasierte Systeme mit lokaler Deep-Learning-Bildverarbeitung sind rechenintensiv und benötigen für Echtzeitbetrieb häufig leistungsfähige Hardware; auf schwächer ausgestatteten Systemen sinkt die Performance deutlich[9].
Diese Arbeit adressiert die beschriebene Lücke durch die Entwicklung und Evaluierung eines cloudbasierten Prototyps zur automatisierten Warteschlangenüberwachung mittels Kameraerfassung und einer KI-gestützten Bildanalyse. Das System ermittelt mithilfe eines Kamerabildes die aktuelle Anzahl wartender Personen und leitet daraus die voraussichtliche Wartezeit sowie die Produktverfügbarkeit ab. Aus diesen beiden Werten entsteht eine intuitive Entscheidungshilfe in Form eines Ampelstatus – Grün (ausreichend Zeit und Produkt erhältlich), Gelb (ausreichend Zeit, Produkt aber voraussichtlich vergriffen) oder Rot (Zeit reicht nicht aus). Ziel ist eine kostengünstige, skalierbare und hardwarearme Lösung, die ohne aktive Mitwirkung der Nutzer auskommt. Als konkreter Anwendungsfall dient die Warteschlangensituation in einer Mensa.
2Stand des Wissens
Warteschlangen-Monitoring und -Analyse verbindet interdisziplinär Warteschlangentheorie, Personenzählung, Bildverarbeitung und Internet of Things (IoT). Dieser Überblick fasst den Stand des Wissens in vier Bereichen zusammen.
Wartezeitvorhersage und Queue Management. Die Vorhersage von Wartezeiten ist zentral für das Queue Management. Loureiro et al.[8] erzielten mittels Machine Learning domänenübergreifende Vorhersagefehler von fünf bis sieben Minuten. Anussornnitisarn und Limlawan[1] zeigten die Überlegenheit neuronaler Netze gegenüber klassischen warteschlangentheoretischen Ansätzen. Für Verkehrsknotenpunkte demonstrierten Rahman und Hasan[10], dass LSTM zeitabhängige Muster präzise abbilden können, während Aydın et al.[11] den Prognosefehler für Kantinenbesucher um 4,7 % reduzierten. Trotz dieser Fortschritte vernachlässigen bestehende Ansätze die Produktverfügbarkeit sowie nutzerorientierte Echtzeit-Entscheidungshilfen.
Kamerabasierte Personenzählung und Crowd-Analyse. Gündüz und Işık[9] evaluierten Varianten des Objekterkennungsmodells YOLO[12] für die Echtzeit-Zählung hinsichtlich Genauigkeit und Latenz. Kumar et al.[13] kombinierten YOLOv7/v8 mit Regressionsalgorithmen für das Queue Monitoring, während Wardihani et al.[14] mittels YOLOv8 auf einem Jetson Nano eine Precision von 0,965 erzielten. Da diese Ansätze lokale Spezialhardware voraussetzen, bleibt der Einfluss von Bildkompression bei cloudbasierter Übertragung weitgehend ungeprüft. Der Cloud-Dienst Amazon Rekognition[15] verlagert die Rechenlast in die Cloud und reduziert damit Anforderungen an lokale Hardware.
IoT- und Cloud-Architekturen für Echtzeitsysteme. Klimek[16] beschrieb ein kontextsensitives System, das Warteschlangenmanagement als Zusammenspiel aus Erfassung, Kontextverarbeitung und nutzerorientierter Handlungsempfehlung versteht. Wang et al.[17] untersuchten serverlose Edge-Cloud-Architekturen für IoT-Anwendungen und zeigten, dass bei MQTT-basierter Übertragung zusätzliche Latenz gegenüber HTTP durch Protokollkonvertierung entsteht. Die Frage, ob eine reduzierte Bildqualität – wie sie bei einer Übertragung via MQTT-Broker mit Payload-Größenbeschränkung entstehen würde – die Erkennungsgenauigkeit beeinflusst, bleibt offen.
Datenschutz bei kamerabasierter Erfassung. Kamerabasierte Personenzählung unterliegt den Anforderungen der DSGVO, insbesondere dem Grundsatz der Datenminimierung gemäß Art. 5 Abs. 1 lit. c[18]. Rusca et al.[19] betonen, dass sowohl vision- als auch gerätebasierte Crowd-Sensing-Ansätze Risiken der individuellen Identifikation bergen, und schlagen datenschutzfreundliche Alternativen auf Basis von WiFi-Fingerprinting vor. Auch das AMS Institute[20] hinterfragt, ob hochauflösende Bilder für die bloße Feststellung einer Überfüllung notwendig sind.
Einordnung. ML-basierte Ansätze[1][8][10][11] fokussieren auf die Wartezeitvorhersage, berücksichtigen jedoch weder die Produktverfügbarkeit noch eine nutzerorientierte Echtzeit-Entscheidungshilfe. Kamerabasierte Systeme[9][13][14] erfordern leistungsfähige lokale Hardware. IoT-basierte Systeme[16][17] setzen komplexe Sensorinfrastrukturen voraus. Die vorliegende Arbeit kombiniert eine cloudbasierte Bildanalyse mittels Amazon Rekognition[15] mit einer dualen Bewertung aus Wartezeit und Produktverfügbarkeit und stellt das Ergebnis als intuitiven Ampelstatus dar. Darüber hinaus untersucht sie, ob eine reduzierte Bildqualität für die cloudbasierte Personenzählung ausreicht und damit dem Grundsatz der Datenminimierung entgegenkommen kann.
3Methodischer Ansatz
Dieses Kapitel stellt den methodischen Ansatz zur Bearbeitung der Problemstellung vor. Ausgehend vom Use Case des Mensa Queue Monitors werden zunächst Zielarchitektur und Umfang des Prototyps erläutert, bevor die Beobachtungsstudie zur durchschnittlichen Bedienzeit und der Evaluierungsansatz beschrieben werden.
3.1Use Case: Mensa Queue Monitor (Meqmon)
Der Mensa Queue Monitor adressiert eine alltägliche Situation an Hochschulen: Studierende verfügen zwischen Lehrveranstaltungen über ein begrenztes Zeitfenster für die Mittagspause. Beim Eintreffen an der Mensa fehlt eine verlässliche Einschätzung, ob die verbleibende Zeit ausreicht, um sich anzustellen und bedient zu werden. Hinzu kommt die Unsicherheit, ob das gewünschte Menü noch erhältlich sein wird. Um diesen Fragen zu begegnen, gibt die nutzende Person auf einer Weboberfläche die verfügbare Zeit in Minuten und das gewünschte Menü ein.
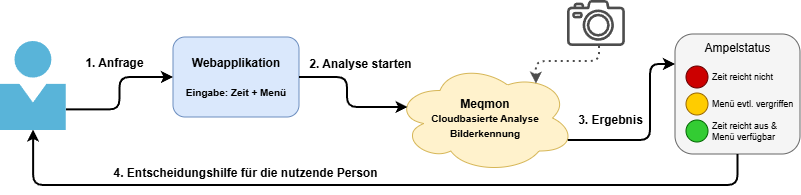
Per Klick auf einen Button wird die Analyse ausgelöst. Auf Basis eines Kamerabildes ermittelt das System die Anzahl der wartenden Personen und leitet daraus zwei Bewertungen ab: (1) die voraussichtliche Wartezeit und (2) die Verfügbarkeit des gewünschten Menüs anhand der verbleibenden Portionen und der Anzahl noch wartender Personen. Beide Bewertungen werden zu einem Ampelstatus zusammengeführt.
3.2Zielarchitektur
Die Architektur des Meqmon basiert auf einem cloudbasierten Ansatz, der bewusst auf lokale Recheninfrastruktur verzichtet. Die Systemkomponenten gliedern sich in drei Ebenen: Erfassung, Verarbeitung und Darstellung.
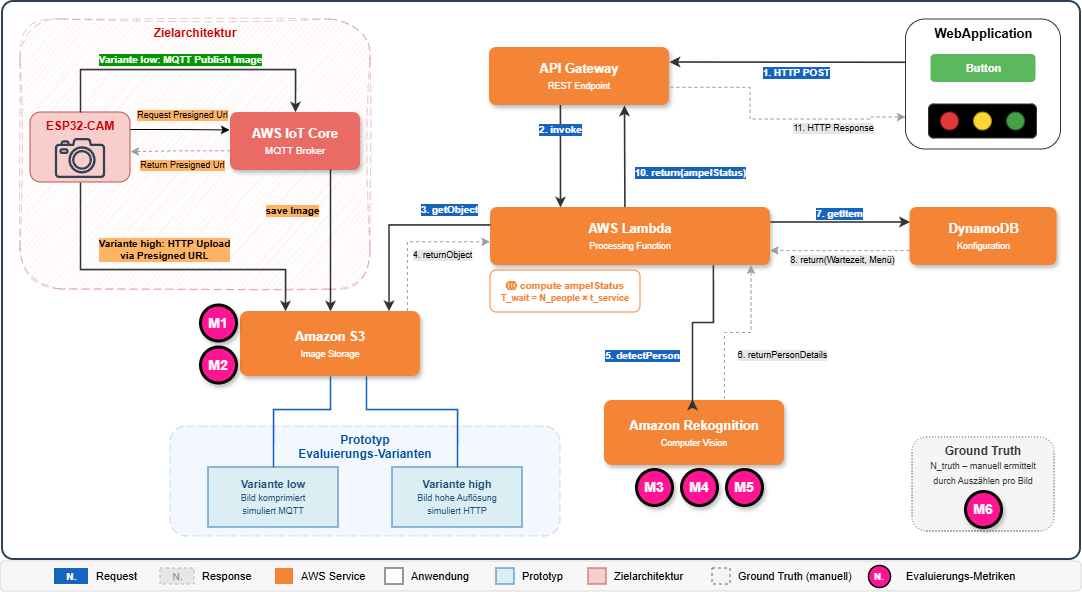
Erfassung. Als Kameramodul ist ein ESP32-CAM vorgesehen, ein kostengünstiger Mikrocontroller mit integrierter Kamera. Das Modul soll auf Anforderung ein Bild der Warteschlange erfassen und an die Cloud übertragen. Dafür sind zwei alternative Wege vorgesehen: über MQTT via AWS IoT Core, wobei das Bild aufgrund der Payload-Größenbeschränkung (128 KB) komprimiert übertragen wird, sowie über HTTP als direkter Upload in einen AWS-S3-Bucket, der eine höhere Auflösung ermöglicht. Im Prototyp werden beide Qualitätsstufen gezielt genutzt, um den Einfluss der Bildauflösung auf die Erkennungsgenauigkeit zu evaluieren.
Verarbeitung. Die serverseitige Verarbeitung erfolgt vollständig in der AWS-Cloud. Eine AWS-Lambda-Funktion wird durch die über das API Gateway eingehende Nutzeranfrage ausgelöst, liest das aktuelle Bild aus Amazon S3 und übergibt es an Amazon Rekognition. Dieser Dienst analysiert das Bild mittels vortrainierter Computer-Vision-Modelle und liefert die Anzahl erkannter Personen sowie für jede Detektion einen Confidence-Wert zurück. Die Lambda-Funktion berechnet anschließend die geschätzte Wartezeit:
Formel (1) setzt eine einzelne Kasse voraus – diese Annahme entspricht der Situation an der untersuchten Mensa, in der die Kasse als zentrale Engstelle von allen Wartenden durchlaufen wird. Parallel wird die Menüverfügbarkeit bewertet, indem die Anzahl der verbleibenden Portionen mit der Zahl der noch wartenden Personen abgeglichen wird.
Darstellung. Das Ergebnis wird auf einer Weboberfläche als Ampelstatus dargestellt – Grün (Zeit und Menü ausreichend), Gelb (Zeit ausreichend, Menü aber eventuell vergriffen), Rot (Zeit nicht ausreichend). Diese Darstellung erfordert keine Interpretation durch die nutzende Person und ermöglicht eine sofortige Entscheidung.
3.3Abgrenzung Prototyp
Der Prototyp setzt die Zielarchitektur bewusst nicht vollständig um, sondern konzentriert sich auf die Verarbeitungs- und Darstellungsebene; der Erfassungsteil mit ESP32-CAM, AWS IoT Core und den beiden physischen Übertragungswegen ist nicht implementiert. Anstelle der physischen Erfassung werden vorgenerierte Warteschlangenbilder in zwei Qualitätsstufen (low, high) direkt in Amazon S3 bereitgestellt. Ab der Bildbereitstellung ist der Prototyp vollständig implementiert: Lambda-Funktion, Analyse durch Amazon Rekognition, Wartezeitberechnung und Ampeldarstellung sind funktionsfähig. Die verbleibenden Portionen werden mangels Schnittstelle zum Mensasystem simuliert.
3.4Beobachtungsstudie zur durchschnittlichen Bedienzeit
Die Wartezeitberechnung setzt die durchschnittliche Bedienzeit pro Person t̄service als Eingangsparameter voraus. Da dieser Wert standortspezifisch ist, wurde er in einer Beobachtungsstudie an der Mensa der Hochschule Burgenland empirisch erhoben; die Vorgehensweise orientiert sich an Yifter et al.[4] Als Bedienzeit wurde die Zeitspanne zwischen Eintreffen an und Verlassen der Kasse operationalisiert. Die Erfassung erfolgte manuell mittels Stoppuhr an mehreren Tagen während der Mittagsöffnung durch zwei unabhängige Beobachter. Insgesamt wurden n = 57 Bedienvorgänge erfasst.
| Kennwert | Wert |
|---|---|
| Arithmetisches Mittel t̄service | 20,17 s |
| Standardabweichung | 10,26 s |
| Median | 17,20 s |
| Getrimmtes Mittel (5 %) | 19,80 s |
Als Wert für t̄service wurde das arithmetische Mittel mit 20,17 s gewählt. Da Twait als Erwartungswert der kumulativen Bedienzeit von Ndetected Personen interpretiert wird, ist der arithmetische Mittelwert die korrekte Wahl; ein Median würde die zu erwartende Gesamtwartezeit systematisch unterschätzen. Die rechtsschiefe Verteilung ist ein strukturelles Merkmal von Servicezeit-Verteilungen; dass das getrimmte Mittel (19,80 s) nur geringfügig abweicht, zeigt, dass Extremwerte den Wert nicht nennenswert verzerren.
3.5Evaluierungsansatz
Die zentrale Evaluierungsfrage lautet: Wie beeinflusst eine reduzierte Bildqualität – wie sie bei einer MQTT-Übertragung auftreten würde – die Erkennungsgenauigkeit von Amazon Rekognition im Vergleich zu einer HTTP-basierten Übertragung mit höherer Bildqualität? Um diese Frage zu beantworten, werden dieselben Warteschlangenszenarien in beiden Qualitätsstufen (low und high) an Amazon Rekognition übermittelt. Die Messpunkte M1–M6 in Abbildung 2 markieren die Stellen, an denen die relevanten Größen erhoben werden.
4Evaluierung und Ergebnisse
Zur Beantwortung der Forschungsfrage wurden 30 Warteschlangenbilder in zwei Qualitätsstufen an die Amazon-Rekognition-Operation DetectLabels übermittelt und ausgewertet.
4.1Testdaten und Ground Truth
Die Evaluierung basiert auf 30 Originalbildern, die drei typischen Szenarien zugeordnet sind: short (0–5 Personen, niedrige Auslastung), middle (6–15 Personen, mittlere Auslastung) und long (ab 16 Personen, hohe Auslastung). Pro Szenario stehen zehn Bilder zur Verfügung. Eines der short-Bilder zeigt bewusst eine leere Warteschlange (Ntruth = 0). Der Großteil der Bilder wurde mit einem generativen KI-Modell (Google Gemini) erzeugt, ergänzt um reale Mensa-Aufnahmen. Als Ground Truth (Ntruth, M6) wurde die tatsächliche Anzahl wartender Personen manuell ausgezählt.
Jedes Originalbild wurde in zwei JPEG-Varianten konvertiert. Die Variante high verwendet maximale JPEG-Qualität (Q=95) bei Originalauflösung und entspricht einer HTTP-Übertragung. Die Variante low verwendet reduzierte Qualität (Q=50) und skaliert die längere Kante auf maximal 1024 Pixel; sie simuliert eine MQTT-typische Übertragung unterhalb der 128-KB-Grenze. Die Dateigrößen der low-Variante lagen zwischen rund 50 KB und 90 KB.
4.2Metriken
| Marker | Größe | Quelle |
|---|---|---|
| M1 | Bildgröße in KB | Dateisystem |
| M2 | Variante (low/high) | Dateiname |
| M3 | Ndetected | Rekognition-Response |
| M4 | Label-Confidence des Person-Labels | Rekognition-Response |
| M5 | Min- und Mean-Confidence über alle Instanzen | Rekognition-Response |
| M6 | Ntruth | manuell, im Dateinamen kodiert |
Da die Label-Confidence (M4) bei nahezu allen Bildern über 95 % liegt, ist sie für den Qualitätsvergleich undifferenziert und wurde nicht in die Aggregation einbezogen. Stattdessen werden Min- und Mean-Confidence der einzelnen Person-Instanzen (M5) herangezogen. Die übrigen Kennzahlen werden aus Ndetected (M3) und Ntruth (M6) berechnet.
Zählgenauigkeit. Pro Bild wird die Differenz Δ, über n Bilder der mittlere absolute Fehler (MAE) und die normierte relative Abweichung δrel bestimmt:
Precision und Recall (zählbasiert). Da der Fokus auf der Zählgenauigkeit liegt, werden Precision und Recall ohne explizites Bounding-Box-Matching definiert. Mit TP = min(Ndet, Ntruth) ergeben sich:
Im Sonderfall Ntruth = 0 (leere Warteschlange) sind Recall und relative Abweichung mathematisch nicht definiert; alle drei Metriken werden daher für diesen Fall aus der Aggregation ausgenommen. Das Bild bleibt jedoch als Falsch-Positiv-Indikator Bestandteil der Auswertung.
4.3Überblick und Gesamtvergleich
Alle 60 Bildvarianten wurden durch Amazon Rekognition ohne technischen Fehler analysiert.
| Kennwert | low | high | Δ (high − low) |
|---|---|---|---|
| Ø Dateigröße (KB) | 64,67 | 1469,63 | +1404,96 |
| Ø Ndetected | 9,67 | 13,37 | +3,70 |
| MAE | 4,67 | 2,37 | −2,30 |
| Ø Min Confidence | 82,86 | 87,13 | +4,27 |
| Ø Mean Confidence | 90,94 | 95,70 | +4,76 |
| Ø Precision | 92,5 % | 87,8 % | −4,7 pp |
| Ø Recall | 83,8 % | 96,4 % | +12,6 pp |
| Ø Relative Abweichung | 27,0 % | 24,4 % | −2,6 pp |
Auf aggregierter Ebene erreicht die high-Variante einen Recall von 96,4 % gegenüber 83,8 % bei low; der mittlere absolute Fehler halbiert sich nahezu von 4,67 auf 2,37. Dem steht ein deutlicher Vorteil im Datenvolumen gegenüber: Bei 64,67 KB gegenüber 1469,63 KB spart low rund 96 % des Datenvolumens ein. Die höhere Precision der low-Variante (92,5 % vs. 87,8 %) ist kein Qualitätsvorteil, sondern eine arithmetische Konsequenz der zählbasierten Definition: Eine starke Unterschätzung erzeugt mechanisch eine hohe Precision.
4.4Ergebnisse pro Szenario
| Szenario | Var. | Ø Ntruth | Ø Ndet | MAE | Ø Recall | Ø Min Conf | Ø Rel. Abw. |
|---|---|---|---|---|---|---|---|
| short | low | 3,2 | 3,9 | 0,7 | 100,0 % | 92,21 | 26,7 % |
| high | 3,2 | 5,1 | 1,9 | 100,0 % | 90,76 | 51,1 % | |
| middle | low | 12,2 | 11,9 | 1,7 | 92,1 % | 82,53 | 14,1 % |
| high | 12,2 | 13,7 | 1,5 | 100,0 % | 87,53 | 12,3 % | |
| long | low | 24,4 | 13,2 | 11,6 | 61,0 % | 73,83 | 40,1 % |
| high | 24,4 | 21,3 | 3,7 | 89,4 % | 83,10 | 12,3 % |
Szenario short (0–5 Personen). Beide Varianten erreichen vollständigen Recall (100 %). Auffällig ist, dass high einen höheren MAE (1,9 vs. 0,7) und mit 51,1 % eine stärkere relative Abweichung aufweist als low (26,7 %) – durch zusätzliche Detektionen feiner Bilddetails, die in der komprimierten Variante entfallen.
Szenario middle (6–15 Personen). Die Varianten liegen dicht beieinander (MAE 1,5 vs. 1,7; rel. Abweichung 12,3 % vs. 14,1 %). high erreicht 100 % Recall, low mit 92,1 % nur leicht darunter – praktisch keine relevante Qualitätsdifferenz.
Szenario long (ab 16 Personen). Hier ändert sich das Bild deutlich: low erkennt im Schnitt nur 13,2 von 24,4 Personen (Recall 61,0 %, MAE 11,6), während high mit 89,4 % Recall und MAE 3,7 deutlich besser abschneidet. Die Min-Confidence der low-Variante liegt mit 73,83 nur knapp über dem Schwellwert von 70.
4.5Diskussion der Befunde
Szenarienabhängigkeit als zentraler Befund. Der Effekt der Bildqualität ist nicht uniform, sondern hängt stark von der Personenzahl ab. Im short- und middle-Szenario sind beide Varianten praktisch gleichwertig, während low im long-Szenario deutlich abfällt. Da eine Wartezeitschätzung gerade bei langen Schlangen den größten Nutzen hat, liefert die komprimierte Variante ihre unsichersten Ergebnisse im praktisch relevantesten Fall.
Verhalten bei leerer Warteschlange. Für das Bild mit leerer Warteschlange liefert Rekognition in der high-Variante vier, in der low-Variante eine Falscherkennung. Für die Ampellogik bleibt der Effekt unkritisch: Selbst vier fälschlich erkannte Personen ergeben nach Formel (1) nur rund 80 Sekunden – ein Wert, der praktisch jede plausible Zeitvorgabe unterschreitet.
Confidence-Werte als ergänzender Indikator. Das Verhältnis der Min-Confidence kippt mit zunehmender Auslastung: Im short-Szenario liegt low noch leicht über high, ab middle kehrt sich das Verhältnis um. Die Min-Confidence erweist sich damit als sensibler Indikator für die Auslastung und käme als Schwellwert für eine Variantenumschaltung in Frage.
Methodische Einordnung der Bildquellen. Ein Großteil der Bilder wurde mit generativer KI erzeugt, was die Übertragbarkeit der absoluten Werte einschränkt. Da jedoch beide Varianten denselben Bildern entstammen, ist der Vergleich zwischen low und high von Bildquellen-Effekten unverzerrt.
Implikationen für den Use Case. Es ergibt sich keine eindeutige Präferenz, sondern eine Abwägung zwischen Bandbreite und Erkennungsqualität: low spart rund 96 % des Datenvolumens und genügt bei niedriger bis mittlerer Auslastung, während high bei hoher Auslastung verlässlichere Ergebnisse liefert.
5Schlussfolgerungen und Ausblick
5.1Zusammenfassung
Zur Bearbeitung der Problemstellung wurde der Mensa Queue Monitor (Meqmon) entwickelt, ein Prototyp auf Basis von AWS Lambda und Amazon Rekognition, der die Anzahl wartender Personen aus einem Kamerabild extrahiert und das Ergebnis als Ampelstatus zurückgibt; ergänzend wurde die durchschnittliche Bedienzeit in einer Beobachtungsstudie (n = 57) empirisch erhoben.
Die zentrale Erkenntnis ist, dass der Einfluss reduzierter Bildqualität auf die Erkennungsgenauigkeit stark szenarienabhängig ist. Bei niedriger und mittlerer Auslastung liefern komprimierte und hochaufgelöste Bilder praktisch gleichwertige Ergebnisse, während die komprimierte Variante bei hoher Auslastung deutlich abfällt (Recall 61,0 % gegenüber 89,4 %). Aus Sicht der Anwendung relativiert sich diese Schwäche jedoch: In der Mehrzahl der Fälle liefert die komprimierte Variante verlässliche Ergebnisse bei rund 96 % reduziertem Datenvolumen, und selbst bei hoher Auslastung trifft auch ein unterschätzter Wartezeitwert oft die richtige Ampelfarbe.
5.2Ausblick
1. Physische Erfassungsebene. Ein reales ESP32-CAM-Modul würde die simulierte Bildbereitstellung in einem produktiven Mensa-Setting ersetzen und die Eignung beider Übertragungswege (MQTT und HTTP) unter realen Bedingungen prüfen.
2. Adaptive Variantenwahl. Da die Min-Confidence sensibel auf die Auslastung reagiert, könnte das System dynamisch zwischen bandbreitensparender low- und hochauflösender high-Variante umschalten – gesteuert über die zuletzt gemessene Personenanzahl oder die Min-Confidence – und so die Vorteile beider Wege kombinieren.
3. Validierung mit realen Aufnahmen. Eine systematische Validierung mit realen Mensa-Aufnahmen würde die absolute Übertragbarkeit der Befunde absichern und ließe sich elegant mit der Realisierung der Erfassungsebene verbinden.
□Literaturverzeichnis
- Anussornnitisarn, P., & Limlawan, V. (2020). Design of advanced queue system using artificial neural network for waiting time prediction. Revista Espacios, 41(40), 111–120.
- Roy, D., Spiliotopoulou, E., & De Vries, J. (2022). Restaurant analytics: Emerging practice and research opportunities. Production and Operations Management, 31(10), 3687–3709. doi:10.1111/poms.13809
- Saaty, T. L. (1961). Elements of Queueing Theory: With Applications. McGraw-Hill.
- Yifter, T., Mengstenew, M., Yoseph, S., & Moges, W. (2023). Modeling and simulation of queuing system to improve service quality at Commercial Bank of Ethiopia. Cogent Engineering, 10(2), 2274522. doi:10.1080/23311916.2023.2274522
- Alghamdi, H., Alshihayb, T. S., Alharbi, Y., Alawagi, M., Aleissa, A., & Albogami, Y. (2025). A data-driven approach to optimizing waiting times in outpatient pharmacy services. Exploratory Research in Clinical and Social Pharmacy, 20, 100672. doi:10.1016/j.rcsop.2025.100672
- Muthu Arumugam, G. R., Muthu Anbananthen, K. S., & Muthaiyah, S. (2025). An IoT BLE based system literature review of real time location monitoring and tracking to shorten patient wait times in Malaysian public hospitals. F1000Research, 14, 568. doi:10.12688/f1000research.160992.1
- Kambli, A., Sinha, A. A., & Srinivas, S. (2020). Improving campus dining operations using capacity and queue management: A simulation-based case study. Journal of Hospitality and Tourism Management, 43, 62–70. doi:10.1016/j.jhtm.2020.02.008
- Loureiro, C., Pereira, P. J., Cortez, P., Guimarães, P., Moreira, C., & Pinho, A. (2023). Predicting multiple domain queue waiting time via machine learning. In ICCSA 2023 (Bd. 13956, S. 404–421). Springer. doi:10.1007/978-3-031-36805-9_27
- Gündüz, M. Ş., & Işık, G. (2023). A new YOLO-based method for real-time crowd detection from video and performance analysis of YOLO models. Journal of Real-Time Image Processing, 20(1), 5. doi:10.1007/s11554-023-01276-w
- Rahman, R., & Hasan, S. (2021). Real-time signal queue length prediction using long short-term memory neural network. Neural Computing and Applications, 33(8), 3311–3324. doi:10.1007/s00521-020-05196-9
- Aydın, B., Balcıoğlu, Y. S., & Sezen, B. (2025). Machine learning techniques for cafeteria demand forecasting: An institutional case. OPUS Journal of Society Research, 22(3), 532–549. doi:10.26466/opusjsr.1649256
- Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2015). You Only Look Once: Unified, real-time object detection. arXiv:1506.02640. doi:10.48550/ARXIV.1506.02640
- Kumar, A., Singh, U., Chatterjee, R., & Bandyopadhyay, T. (2024). Massimo: Public queue monitoring and management using mass-spring model. arXiv:2410.16012. doi:10.48550/arXiv.2410.16012
- Wardihani, E. D., et al. (2025). Human detection system using machine learning to calculate crowd potential. International Journal on Advanced Science, Engineering and Information Technology, 15(1), 60–66. doi:10.18517/ijaseit.15.1.20327
- Amazon. (2026). Amazon Rekognition Documentation. docs.aws.amazon.com/rekognition
- Klimek, R. (2020). Sensor-enabled context-aware and pro-active queue management systems in intelligent environments. Sensors, 20(20), 5837. doi:10.3390/s20205837
- Wang, I.-C., Qi, S., Liri, E., & Ramakrishnan, K. K. (2021). Towards a proactive lightweight serverless edge cloud for Internet-of-Things applications. In 2021 IEEE NAS (S. 1–4). doi:10.1109/NAS51552.2021.9605384
- Europäisches Parlament und Rat der Europäischen Union. (2016). Verordnung (EU) 2016/679 (Datenschutz-Grundverordnung), Art. 5(1)(c).
- Rusca, R., Gasco, D., Casetti, C., & Giaccone, P. (2024). Privacy-preserving WiFi fingerprint-based people counting for crowd management. Computer Communications, 225, 339–349. doi:10.1016/j.comcom.2024.07.010
- Vaidya, G., & Turel, T. (2023). Privacy Preserving Crowd Sensing Systems. Amsterdam Institute for Advanced Metropolitan Solutions.